Visual Studio CodeでC#のコンソールアプリを作成する
公式を読めばわかるのですが,毎回ググっているので備忘録としてまとめておきます.

プロジェクトの作成
VSCodeでCtrl+@でターミナルを開き,以下のように入力するとC#のプロジェクトが作成されます.このとき,プロジェクト名はフォルダ名になります.
dotnet new console
依存パッケージなどがインストールされ,HelloWorldプロジェクトが自動生成されます.また,以下のような警告がでますので,Yesを選択します.

アプリの実行
dotnet run
アプリの発行
dotnet publish --configuration Release
-
- configurationは-cでも大丈夫です.
bin/Release/net5.0/publishフォルダに出力されたファイル一式を配布することで,作成したアプリを他のPCでも実行することが可能です.(pdbファイルは無くても大丈夫です)
自己完結型アプリを発行する
上記「アプリの発行」で作成したアプリは.NETが入っていないPCでは動きません..NETがないPCでも動作可能なアプリを発行するには以下のようにします.
dotnet publish -c Release -r win-x64
win-x64のところはここを参照して適宜変更します.このやり方ですとbin/Release/net5.0/win-x64/publishフォルダに数百のファイルが出力されます.次はこれをすっきりさせる方法です.
単一ファイルのアプリを発行する
csprojに以下のように追記してから先ほどと同じように自己完結型アプリを発行すると生成されるファイル数がだいぶ減ります(単一にはならないですけど...).
<PropertyGroup> <PublishSingleFile>true</PublishSingleFile> </PropertyGroup>
Rのカルマンフィルタライブラリ、KFASの結果解釈備忘録
この本を読んで勉強していますがすぐに忘れてしまうので備忘録として.
ローカル線形トレンドモデル
ローカル線形トレンドモデルの状態方程式,観測方程式は,
なので一般形との対応は,
教科書第5部9章のサンプルを追試してみます.
mod <- SSModel(sales_train ~ SSMtrend(2, Q=c(list(NA), list(NA))), H=NA) fit <- fitSSM(mod, rep(1, 3)) kfs <- KFS(fit$model, filtering = c("state", "mean"), smoothing = c("state", "mean"))
観測誤差の分散は約24となり信の値25に近い推定値が得られています.
> fit$model$H , , 1 [,1] [1,] 23.63745
同様に,過程誤差の分散は,水準の変動が0.88(真の値1),トレンドの変動が0.00046(真の値0)となり,どちらも真の値に近い推定値が得られています.
> fit$model$Q , , 1 [,1] [,2] [1,] 0.8833319 0.0000000000 [2,] 0.0000000 0.0004648067
その他の要素も上記定式化の通りであることを確認できます.
> fit$model$T , , 1 level slope level 1 1 slope 0 1 > fit$model$R , , 1 [,1] [,2] level 1 0 slope 0 1 > fit$model$Z , , 1 level slope [1,] 1 0
推定された平滑化状態はkfs$alphahatに格納されており,levelが水準(),slopleがトレンド(
)です.
> head(kfs$alphahat, n=3) level slope [1,] 7.592715 0.1979556 [2,] 7.573414 0.1980699 [3,] 7.817400 0.1981601
ここで,教科書p.255にも記載がありますが,ここで推定したトレンドは状態の推定値であって観測値ではないことに注意が必要です.
上で定式化したように,観測値はこの累積和になっています.
kfs$aをみると最後(t=401)の時点での水準値とトレンド値を得られます.
> tail(kfs$a, n=2) level slope [400,] 47.12591 -0.09044255 [401,] 44.60478 -0.13952919
ここから,t=402の推定値は,
と求まります.同様に,
となります.これらはpredictの結果と一致します.
> predict(fit$model, interval="prediction", level=0.9, n.ahead=3) Time Series: Start = 401 End = 403 Frequency = 1 fit lwr upr 401 44.60478 35.70135 53.50821 402 44.46525 35.39030 53.54020 403 44.32572 35.07563 53.57581
予測区間については,KFASのソースコードから,
と求めているのは分かるのですが,が何なのかまだ理解できていません...
追記
こちらの本によるとは平滑化状態分散というそうです.
ダミー変数を用いた周期成分
例えば週次変動を考慮する場合,6つのダミー変数を用意します.このとき一般式は次のようになります.
時系列予測ツールProphetの使い方備忘録
Facebookが提供している時系列予測ツールのOSS,Prophetの使い方を備忘録的に残しておきます*1.
動作確認したProphetのバージョンは1.0です.
- 基本的な使い方
- 飽和するトレンドのモデリング
- トレンドの変化点のモデリング
- 季節成分のモデリング
- 祝日やイベントのモデリング
- 季節成分,イベントの影響度調整
- 回帰項の追加
- 季節成分(やイベント成分)の乗算
- 不確定区間
- 外れ値の扱い
- 時間軸や月次の予測
- 交差検証によるハイパーパラメータチューニング
- モデルのセーブとロード
基本的な使い方
library(prophet) # 必須カラムはds(日付)とy(目的変数) # ds列のフォーマットはYYYY-MM-DDかYYYY-MM-DD HH:MM:SS df <- read.csv('../examples/example_wp_log_peyton_manning.csv') # モデルのfit m <- prophet(df) # 予測結果格納用データフレームの作成 # 学習期間も含むので注意 future <- make_future_dataframe(m, periods = 365) # 予測 forecast <- predict(m, future) # 結果の描画 plot(m, forecast) # 各成分の描画 prophet_plot_components(m, forecast)
飽和するトレンドのモデリング
Prophetはロジスティック曲線を使って飽和するトレンドをモデリングできます.
トレンドの上限はcapを,下限はfloorをdfの新たな列として加えます.これらの値は全行で同じ値である必要はありません.
df$cap <- 8.5 df$floor <- 1.5 m <- prophet(df, growth = 'logistic') future <- make_future_dataframe(m, periods = 1826) future$cap <- 8.5 future$floor <- 1.5 fcst <- predict(m, future)
トレンドの変化点のモデリング
Prophetはトレンドの変化点の候補を多めに(初期値は25)見積もり,L1正則化のような形で変化点の絞り込みを行います.変化点の候補はデフォルトでは時系列データの先頭から80%の時点から抽出されます(予測が最後の方の変化に引きずられないようにするため).
変化点候補の数はn.changepointsパラメータで,変化点抽出レンジはchangepoint.rangeパラメタ(0~1)で調整できます.
抽出された変化点は以下のようにして可視化できます.
plot(m, forecast) + add_changepoints_to_plot(m)
トレンド変化への追従度合いはchangepoint.prior.scaleパラメータで変更できます.初期値は0.05で大きくすると追従しやすくなります.このパラメータは後述する交差検証でチューニングすることができます.
変化点は以下のように明示的にしていすることもできます.
m <- prophet(df, changepoints = c('2014-01-01'))
季節成分のモデリング
ここでいう季節とは四季のことではなく,年次や週次の周期性のことです.
Prophetは年次,週次,日次の周期性モデリングをデフォルトでサポートしており,以下のように書くことができます.
m <- prophet(df, weekly.seasonality = TRUE, yearly.seasonality = TRUE, daily.seasonality=FALSE)
季節成分はどのくらい高周波成分に追従するかというハイパーパラメータを持っています.これを調整する場合は,bool値ではなく数値を指定します.yearly.seasonalityの初期値は10,weekly.seasonalityの初期値は3です(daily.seasonalityの初期値は分かりませんでした).
季節成分は以下のように可視化することができます.
prophet:::plot_yearly(m)
月次の周期性のように新たな季節成分を取り入れたいときは以下のようにします.fourier.orderは先の高周波成分への追従性に対するハイパーパラメータです.
m <- prophet(weekly.seasonality=FALSE, yearly.seasonality=FALSE) m <- add_seasonality(m, name='monthly', period=30.5, fourier.order=5) m <- fit.prophet(m, df)
条件付き季節性
Prophetのチュートリアルで使われる,Wikipediaのペイトン・マニング(アメフトの選手)の検索数において,週次成分がオンシーズンとオフシーズンで異なるという仮説を立てた場合,以下の用の考慮することができます.
m <- prophet(weekly.seasonality=FALSE) m <- add_seasonality(m, name='weekly_on_season', period=7, fourier.order=3, condition.name='on_season') m <- add_seasonality(m, name='weekly_off_season', period=7, fourier.order=3, condition.name='off_season') m <- fit.prophet(m, df)
デフォルトのweekly.seasonalityをオフにし,新たに独自の週次成分を2つ追加します.
こららの成分はdfに新たに追加されたbool値の変数,on_seaon,off_seaonがTRUEのときのみ有効になります.
祝日やイベントのモデリング
以下のようなcsvファイルを用意します.
必須な列はヘッダ名がholidayの列とdsの列です.
holiday列にイベント名を,ds列にそのイベントの発生日を入れます.
このデータには,予測期間の情報も含まれている必要があります.
lower_window,upper_window列は,そのイベントの前後への影響日数を記載します.
例えばクリスマスというholidayのイベント(2021-12-25)に対し,クリスマスイブも考慮したい場合は,
lower_windowを-1とします.
この表の例では,superbowlsの日付はplayoffの日付と重複しています.
このような場合,playoffの効果にsuperbowlsの効果が加算されます.
| holiday | ds | lower_window | upper_window |
|---|---|---|---|
| playoff | 2008-01-13 | 0 | 1 |
| playoff | 2009-01-03 | 0 | 1 |
| playoff | 2010-01-16 | 0 | 1 |
| playoff | 2010-01-24 | 0 | 1 |
| playoff | 2010-02-27 | 0 | 1 |
| playoff | 2011-01-08 | 0 | 1 |
| playoff | 2013-01-12 | 0 | 1 |
| playoff | 2014-01-12 | 0 | 1 |
| playoff | 2014-01-19 | 0 | 1 |
| playoff | 2014-02-02 | 0 | 1 |
| playoff | 2015-01-11 | 0 | 1 |
| playoff | 2016-01-17 | 0 | 1 |
| playoff | 2016-01-24 | 0 | 1 |
| playoff | 2016-02-07 | 0 | 1 |
| superbowls | 2010-02-07 | 0 | 1 |
| superbowls | 2014-02-02 | 0 | 1 |
| superbowls | 2016-02-07 | 0 | 1 |
このデータを以下のように読み込みます.
df <- read.csv("example_wp_log_peyton_manning.csv") holidays <- read.csv("holidays.csv") m <- prophet(df, holidays = holidays)
季節成分,イベントの影響度調整
季節成分やイベントの影響がややデータに対し過剰適応気味だと判断した場合,seasonality_prior_scale,holidays_prior_scaleを小さくすることで対応できます.初期値は10です.
m <- prophet(df, holidays = holidays, holidays.prior.scale = 0.05)
イベントごとに影響度を調整したい場合,データフレームholidaysにprior_scaleの列を追加します.
年次や週次の成分ごとに影響度を調整したい場合,add_seasonalityのハイパーパラメータ,prior.scaleで調整します.
m <- add_seasonality(m, name='weekly', period=7, fourier.order=3, prior.scale=0.1)
回帰項の追加
いわゆる外生変数は以下のように追加できる(元のdfに新たな列nlf_sundayが追加されているものとする).
m.add_regressor('nfl_sunday') m.fit(df)
外生変数が0/1の場合はイベントとして扱うこともできる.0/1以外の変数も加えることができる(アイスクリームの売り上げ予測に気温を使うなど)が,その値の未来の値が手に入るかをよく考える必要がある.
外生変数の係数はprophet::regressor_coefficientsで確認することができる.
季節成分(やイベント成分)の乗算
デフォルトでは季節成分やイベント成分はトレンド成分に加算されますが,例えばトレンドの上昇に伴い季節成分の増減も大きくなっていくような場合,以下のようにすると季節成分の(デフォルトではイベント成分や外生成分も同様に)影響を乗算することができます.
m <- prophet(df, seasonality.mode = 'multiplicative')
ある成分は乗算,別の成分は加算したい場合は以下のようにします(が本当にそのようなモデリングが妥当かはよく考える必要があります).
m <- prophet(seasonality.mode = 'multiplicative') m <- add_seasonality(m, 'quarterly', period = 91.25, fourier.order = 8, mode = 'additive') m <- add_regressor(m, 'regressor', mode = 'additive')
不確定区間
トレンドの不確定区間*2(デフォルトは0.8)は以下のように変更することができます.
m <- prophet(df, interval.width = 0.95)
季節成分の不確定区間もみたいばあい,以下のようにMAP推定ではなくMCMCサンプリングを使う必要があります.
m <- prophet(df, mcmc.samples = 300)
生の事後予測サンプルはpredictive_samples(m, future)で得ることができます.ちなみに,WindowsのPythonのPyStanは非常に遅いので,MCMCサンプリングをしたい場合は,Rを使うか,LinuxのPythonを使うのがよいそうです.
外れ値の扱い
外れ値があると予測値の不確定区間が非常に大きくなってしまいます.Prophetは欠損値を扱うことができるので,外れ値の影響を軽減したければ,外れ値をNAにすることで対応できます.
outliers <- (as.Date(df$ds) > as.Date('2010-01-01') & as.Date(df$ds) < as.Date('2011-01-01')) df$y[outliers] = NA m <- prophet(df)
時間軸や月次の予測
時間軸の予測をするさいに,もしデータが午前中のデータしか含まないような場合,futureデータフレームもどうようの形式に合わせてあげればよい.
future2 <- future %>% filter(as.numeric(format(ds, "%H")) < 6) fcst <- predict(m, future2)
月次のデータを扱う場合,dtをYYYY-MM-01のような形で記載すればよい.このとき,予測を月次で行うには以下のように記載する.
future <- make_future_dataframe(m, periods = 120, freq = 'month')
交差検証によるハイパーパラメータチューニング
ハイパーパラメータをチューニングするために交差検証をすることができます.
df.cv <- cross_validation(m, initial = 730, period = 180, horizon = 365, units = 'days')
initialが訓練期間,horizonが検証期間,periodがスライド幅です.ペイトン・マニングのサンプルデータ(2007/12/10~2016/1-20)に対して上記のコードを実行した場合,Cutoff date(検証期間の初日)は,
'10/2/15,'10/8/14,'11/2/10,'11/8/9,'12/2/5,'12/8/3,
'13/1/30,'13/7/29,'14/1/25,'14/7/24,'15/1/20
の11か所になります('10/2/15から180日遡るとデータ始点まで618日となり730日が確保できないため).
Rでは,unitsはweeksより短い必要があるようです.
以下のように独自のカットオフ日を設定することもできます.
cutoffs <- as.Date(c('2013-02-15', '2013-08-15', '2014-02-15')) df.cv2 <- cross_validation(m, cutoffs = cutoffs, horizon = 365, units = 'days')
交差検証の結果の要約統計量はperformance_metricsで,プロットはplot_cross_validation_metricで確認することができます.
df.p <- performance_metrics(df.cv) plot_cross_validation_metric(df.cv, metric = 'mape')
Pythonですと交差検証の並列実行ができるようですが,Rには用意されていないようです.
Prophetのドキュメントで推奨されているチューニングすべきハイパーパラメータは,changepoint,seasonality,holidaysのprior scaleと,seasonality_mode(additive or multiplicative)です.
年次,週次,日次の周期性を見るかどうかのオプションはデータの取得期間で決めればよいと記載されています(複数年のデータであっても年次の周期性が明確にみられなければFALSEにしてもよい気がしますが).
モデルのセーブとロード
saveRDS(m, file="model.RDS") # Save model m <- readRDS(file="model.RDS") # Load model
RでStan(事後予測チェック)
外部ライブラリの準備
install.packages("bayesplot") install.packages("dplyr") library(bayesplot)
MCMCの結果のプロットに便利なbayesplotを入れます.なぜか依存パッケージのdplyrが自動で入らなかったので別途入れる必要がありました.
問題設定
ある小動物の発見個体数のモデル化に取り組みます.
群れを作ることなくランダムに生息している動物がある観測地点において発見された個体数を扱います.
個の場合,小動物の発見個体数データが得られる確率的な家庭はポアソン分布だと考えられます.
そこで,ポアソン分布でモデル化するケースと,あえて誤ったモデルとして正規分布でモデル化するケースを考えます.
実装
Rファイル
library(rstudioapi) library(rstan) library(bayesplot) rstan_options(auto_write=TRUE) # 2回目以降のコンパイルを不要にする options(mc.cores=parallel::detectCores()) # 計算の並列化 animal_num <- read.csv("2-5-1-animal-num.csv") data_list <- list(animal_num=animal_num$animal_num, N=nrow(animal_num)) mcmc_normal <- stan( file = "2-5-1-normal-dist.stan", data = data_list, seed = 1 ) mcmc_poisson <- stan( file = "2-5-1-poisson-dist.stan", data = data_list, seed = 1 )
Stanファイル
正規分布
data {
int N;
vector[N] animal_num;
}
parameters {
real<lower=0> mu;
real<lower=0> sigma;
}
model {
animal_num ~ normal(mu, sigma);
}
generated quantities{
// 事後予測分布を得る
vector[N] pred;
for (i in 1:N){
pred[i] = normal_rng(mu, sigma);
}
}
ポアソン分布
data {
int N;
int animal_num[N];
}
parameters {
real<lower=0> lambda; // 強度
}
model {
// 強度lambdaのポアソン分布
animal_num ~ poisson(lambda);
}
generated quantities{
// 事後予測分布を得る
int pred[N];
for (i in 1:N){
pred[i] = poisson_rng(lambda);
}
}generated quantitiesブロックは「モデル推定以外の目的で乱数を得たいモノ」を指定するブロックで,モデルを用いた予測値などをここに記述します.
normal_rng,poisson_rngメソッドを使うことで正規分布,ポアソン分布に従う乱数をpredに格納します.
結果の確認
y_rep_normal <- rstan::extract(mcmc_normal)$pred y_rep_poisson <- rstan::extract(mcmc_poisson)$pred ppc_hist(y=animal_num$animal_num, yrep = y_rep_normal[1:5,]) ppc_hist(y=animal_num$animal_num, yrep = y_rep_poisson[1:5,])

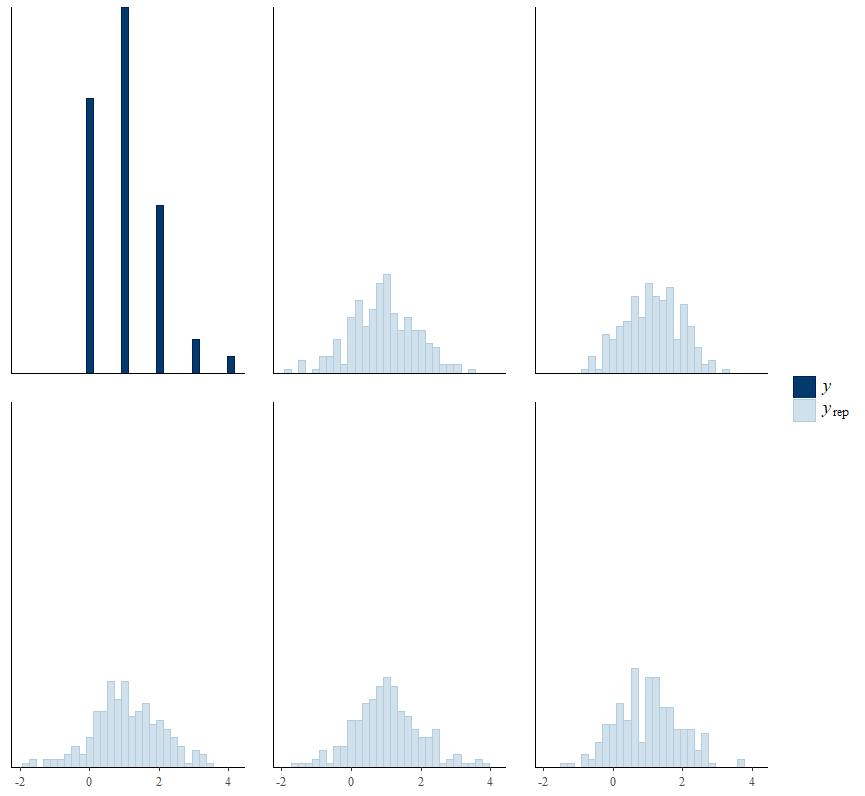
観測データの分布と,1~5回目のMCMCサンプルのヒストグラムを比較することで,ポアソン分布でもモデル化した方はそれっぽい結果になっているのに対し,正規分布でモデル化した方は観測データの分布と大きく異なっていることが確認できます.
RでStan(基本)
RからStanを使うための勉強をしていきます.
rstanとRtoolsのインストール
> install.packages('rstan', repos='https://cloud.r-project.org/', dependencies=TRUE) > pkgbuild::has_build_tools(debug=TRUE) > install.packages("rstudioapi")
テキストにはrstudioapiが必要とは書いてありませんでしたが,RStudioを使って並列計算をする場合に必要なようです.
また,
C:\RBuildTools\4.0\usr\bin
C:\RBuildTools\4.0\mingw64\bin
にパスを通す必要がありました.
実装
Stanファイル
// 使用するデータ
data {
int<lower=0> N;
vector[N] sales;
}
// 事後分布を得たいパラメータの一覧
parameters {
real mu;
real<lower=0> sigma;
}
// 売り上げという観測データは平均mu,標準偏差sigmaの正規分布から得られた
// ということを表すモデル
model {
for (i in 1:N){
sales[i] ~ normal(mu, sigma);
}
}modelブロックはforループを使わずに
sales ~ normal(mu, sigma);
と書くこともできます.このような書き方をベクトル化と呼びます.ベクトル化すると計算が速くなることがあるそうです.
Rファイル
library(rstudioapi) library(rstan) # 計算の高速化 rstan_options(auto_write=TRUE) # 2回目以降のコンパイルを不要にする options(mc.cores=parallel::detectCores()) # 計算の並列化 beer_df <- read.csv("2-4-1-beer-sales-1.csv") data_list <- list(sales=beer_df$sales, N=nrow(beer_df)) mcmc_result <- stan( file = "2-4-1-calc-mean-variance.stan", data = data_list, seed = 1, chains = 4, iter = 2000, warmup = 1000, thin = 1 )
stanメソッドに渡すデータはデータリスト形式で,Stanファイルに記載した変数が格納されている必要があります.
iterは生成する乱数の個数です.warmupは乱数の初期値依存性を減らすために切り捨てるサンプルの数です.つまり2000個生成した乱数の内最初の1000個を捨てることになります.
乱数は自己相関を持つこともあるため,thinを1より大きい値にするとthin個の乱数の内1つだけを採用するように間引くことで自己相関の影響を削減できます.
収束の評価を行うために乱数生成を複数セット行います.このセット数をchainsで設定します.
結果の確認
> print( + mcmc_result, + probs = c(0.025, 0.5, 0.975) + ) Inference for Stan model: 2-4-1-calc-mean-variance. 4 chains, each with iter=2000; warmup=1000; thin=1; post-warmup draws per chain=1000, total post-warmup draws=4000. mean se_mean sd 2.5% 50% 97.5% n_eff Rhat mu 102.18 0.03 1.82 98.57 102.20 105.73 3277 1 sigma 18.20 0.02 1.29 15.95 18.12 21.00 2858 1 lp__ -336.44 0.02 0.97 -338.98 -336.12 -335.48 1774 1 > traceplot(mcmc_result)
実行時に以下のような警告がでましたが原因がわかりませんでした.エラーではないのでとりあえず無視してよいのでしょうか?
警告メッセージ: system(paste(CXX, ARGS), ignore.stdout = TRUE, ignore.stderr = TRUE) で: 'C:/RBUILD~1/4.0/usr/mingw_/bin/g++' not found
n_effはMCMCにおける有効サンプルサイズだそうです.これが少ないようであればモデルの改善が必要であり,100くらいあることが望ましいそうです.
収束判定指標Rhatは1.1未満であることが求められます.
トレースプロットは4本のチェーンがまじりあっていればOKです.
inc_warmup=TRUEとするとwarmup期間を含めて描画できます.
ggplot2を使ったグラフ描画
仕事で時系列データ分析をする必要があり,状態空間モデルを使ってみようと思ったのですが,PythonよりRの情報が多いため,まずはRの復讐から始めます.
この記事ではggplot2を用いたグラフ描画方法を備忘録として残しておきます.
ggplot2パッケージのインストールと読み込み
> install.packages("ggplot2") > library(ggplot2)
データの準備
> fish <- read.csv("2-2-1-fish.csv") > head(fish, n=3) length 1 8.747092 2 10.367287 3 8.328743
ヒストグラム
ggplot(data=fish, mapping=aes(x=length)) + geom_histogram(alpha=0.5, bins=20) + labs(title="ヒストグラム")
mapping=aes(x=length)で横軸に来る変数を指定しています.
aes関数はaesthetic attributeの意味で,各軸の変数や見た目の属性を指定します.
data=,mapping=は省略可能です.
ここまでがグラフのベース部分になります.
今回はここに,geom_histogramを足し合わせ,最後にlabsを使ってグラフのタイトルを足し合わせています.
カーネル密度推定
ggplot(data=fish, mapping=aes(x=length)) + geom_density(size=1.0) + labs(title="カーネル密度推定")
sizeは線の太さです.
グラフの重ね合わせ
ggplot(data=fish, mapping=aes(x=length, y=..density..)) + geom_histogram(alpha=0.5, bins=20) + geom_density(size=1.0) + labs(title="グラフの重ね合わせ")
y=..density..でヒストグラムの面積が1になるようにしています.そうしないとカーネル密度推定の結果をY軸のレンジが違いすぎて見づらくなります.
グラフを並べる
library(gridExtra) p_hist <- ggplot(data=fish, mapping=aes(x=length)) + geom_histogram(alpha=0.5, bins=20) + labs(title="ヒストグラム") p_density <- ggplot(data=fish, mapping=aes(x=length)) + geom_density(size=1.0) + labs(title="カーネル密度推定") grid.arrange(p_hist, p_density, ncol=2)
gridExtraというライブラリを使います.
箱ひげ図とバイオリンプロット
ggplot(data=iris, mapping=aes(x=Species, y=Petal.Length)) + geom_boxplot() + labs(title="箱ひげ図") ggplot(data=iris, mapping=aes(x=Species, y=Petal.Length)) + geom_violin() + labs(title="バイオリンプロット")
散布図
ggplot(iris, aes(x=Petal.Width, y=Petal.Length, color=Species)) + geom_point()
color=Speciesでアヤメの種類別に色分けしています.
折れ線グラフ
nile_df <- data.frame( year = 1871:1970, Nile = as.numeric(Nile) ) ggplot(nile_df, aes(x=year, y=Nile)) + geom_line()
折れ線グラフのサンプルにRに最初から用意されているNileデータを使いますが,Nileデータは時系列データであり,ggplotに渡す前にデータフレーム型に変換が必要となります.
機械学習の知識習得とデータ分析を同時に支援するMALSS interactive
この記事は,機械学習工学 / MLSE Advent Calendar 2018 - Qiitaの2日目の記事です.
tl;dr
機械学習を利用したデータ分析をインタラクティブにサポートしながら,同時にユーザのデータ分析に関する知識習得を支援するPythonライブラリ「MALSS interactive」を作りました.
評価実験に協力してくれる方を絶賛募集中です.
背景と動機
機械学習ブームのおかげで書籍やブログ,オンライン学習コンテンツが充実し,機械学習の勉強・情報収集はとてもやりやすくなりました.
さらに,機械学習の社会実装が進むにつれ,機械学習を用いたデータ分析のプロセスを自動化するツール・サービスも充実してきています.
しかし,忙しいエンジニアは,実務で機械学習を利用するまえに十分に勉強する時間を確保することが困難です.
また,分析の自動化に頼ってしまうと,分析の中身がブラックボックスになり知識が身につかず,より発展的な分析を行うことが難しくなります.
私は機械学習の初学者が勉強をしながら分析を半自動で行うことができるPythonライブラリ,MALSS(MAchine Learning Support System)を開発しています.
Pythonでの機械学習を支援するツール MALSS(導入) - Qiita
MALSSはデータの前処理,アルゴリズム選択,ハイパーパラメータチューニングといった一連の分析手順を自動化します.さらに分析結果をレポートとして出力することで,利用者の知識習得を支援します.
しかし,MALSSはデータの性質や分析結果に応じて動的に分析方法を変えることはできませんでした(そのような作業はMALSS利用の前後で行うことを想定していました).
提案
MALSSを改良し,GUIを備え,ユーザとインタラクティブに分析を進めていくことができる,MALSS interactiveを開発しました.
GitHub - canard0328/malss: MAchine Learning Support System
使い方
MALSSはpipでインストールできます.MALSS interactiveのGUIはPyQt5で作っていますが,MALSSと同時にはインストールされないため,別途PyQt5をインストールする必要があります.
pip install malss pip install pyqt5
インストールが完了したらPythonインタープリタを起動し,以下のようにMALSSをインタラクティブモードで起動します(lang='jp'を忘れると下手くそな英語が出てきますのでご注意ください...).
from malss import MALSS MALSS(interactive=True, lang='jp')
MALSS interactiveが起動すると,あとは画面の指示に従いながら分析を行うことができます.その際,例えば下図のように,変数の種類(量的変数,質的変数)の説明,ダミー変数の説明などを行い,データ読み込み結果に応じて,変数の種類をユーザが変更することができたりします.


グリッドサーチによるハイパーパラメータチューニングもサポートしています.
